視覺(jué)表現(xiàn)方式SEARCH AGGREGATION


回答:在Linux中,創(chuàng)建快捷方式可以使用符號(hào)鏈接(Symbolic Link)來(lái)實(shí)現(xiàn)。以下是創(chuàng)建快捷方式的步驟: 1. 打開(kāi)終端并進(jìn)入要?jiǎng)?chuàng)建快捷方式的目錄。 2. 使用`ln -s`命令來(lái)創(chuàng)建符號(hào)鏈接。該命令的一般語(yǔ)法如下: ln -s 例如,如果要在當(dāng)前目錄下創(chuàng)建一個(gè)指向`/home/user/documents`目錄的符號(hào)鏈接,可以執(zhí)行以下命令: ...
 yunhao
|
1091人閱讀
yunhao
|
1091人閱讀
問(wèn)題描述:關(guān)于企業(yè)銀行如何在線(xiàn)付款方式這個(gè)問(wèn)題,大家能幫我解決一下嗎?
 王巖威
|
455人閱讀
王巖威
|
455人閱讀
問(wèn)題描述:關(guān)于萬(wàn)維網(wǎng)中信息以什么方式這個(gè)問(wèn)題,大家能幫我解決一下嗎?
 劉厚水
|
610人閱讀
劉厚水
|
610人閱讀

...極深的技術(shù),首次系統(tǒng)表達(dá)了自己的產(chǎn)品理念,而大會(huì)主視覺(jué)也始終緊貼著這一理念進(jìn)行設(shè)計(jì)。本文將具體介紹我們的設(shè)計(jì)思路和主要過(guò)程。 關(guān)于設(shè)計(jì)原則:知覺(jué)律與格式塔原理 1910年,心理學(xué)家Max Wertheimer在鐵道口觀察...
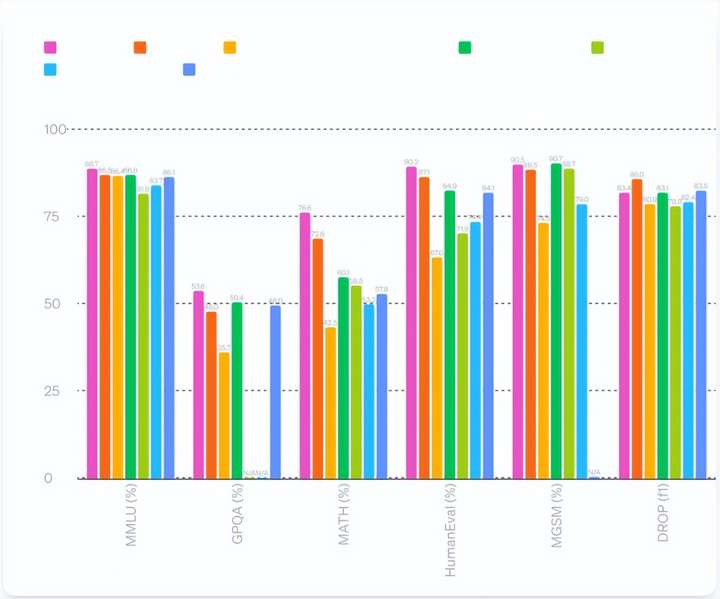
...興地宣布,推出了全新的旗艦?zāi)P?GPT-4o,能夠在音頻、視覺(jué)和文本之間實(shí)時(shí)進(jìn)行推理。GPT-4o(o代表omni 全方位)能夠?qū)崟r(shí)處理音頻、視覺(jué)和文本信息,使人機(jī)交互更加自然流暢。這款模型支持多種輸入(文本、音頻、...
...7 月 26 日,將標(biāo)志著一個(gè)時(shí)代的終結(jié)。那一天,與計(jì)算機(jī)視覺(jué)頂會(huì) CVPR 2017 同期舉行的 Workshop——超越 ILSVRC(Beyond ImageNet Large Scale Visual Recogition Challenge),將宣布計(jì)算機(jī)視覺(jué)乃至整個(gè)人工智能發(fā)展史上的里程碑——IamgeNet ...
...做了實(shí)驗(yàn),然后寫(xiě)了篇論文。他們指出,在深度模型中,視覺(jué)任務(wù)性能隨訓(xùn)練數(shù)據(jù)量(取對(duì)數(shù))的增加,線(xiàn)性上升。以下是Google Research機(jī)器感知組指導(dǎo)教師,卡耐基梅隆大學(xué)助理教授Abhinav Gupta對(duì)這項(xiàng)工作的介紹,發(fā)布在Google Research...
摘要: 深度學(xué)習(xí)大潮為什么淹沒(méi)傳統(tǒng)的計(jì)算機(jī)視覺(jué)技術(shù)?聽(tīng)聽(tīng)大牛怎么說(shuō)~ 這篇文章是受到論壇中經(jīng)常出現(xiàn)的問(wèn)題所創(chuàng)作的: 深度學(xué)習(xí)是否可以取代傳統(tǒng)的計(jì)算機(jī)視覺(jué)? 這明顯是一個(gè)很好的問(wèn)題,深度學(xué)習(xí)(DL)已經(jīng)徹底改...
...實(shí)現(xiàn)以及論文鏈接。為保證文章簡(jiǎn)明,我只總結(jié)了計(jì)算機(jī)視覺(jué)領(lǐng)域的成功架構(gòu)。什么是高級(jí)架構(gòu)?相比于單一的傳統(tǒng)機(jī)器學(xué)習(xí)算法,深度學(xué)習(xí)算法由多樣化的模型組成;這是由于神經(jīng)網(wǎng)絡(luò)在構(gòu)建一個(gè)完整的端到端的模型時(shí)所提供...
最初針對(duì)視覺(jué)信號(hào)設(shè)計(jì)出來(lái)的 CNN 也能處理聽(tīng)覺(jué)信號(hào),最終幫助機(jī)器傾聽(tīng)和更好地理解我們。 CNN 在某些程度上能遷移學(xué)習(xí),掌握多種模式的共同特征。有一系列神經(jīng)網(wǎng)絡(luò)機(jī)器學(xué)習(xí)方法不只是「有深度的」。在這段時(shí)間,針對(duì)先...
...l.edu/papers/olshausen_field_1997.pdf) 表明,編碼理論可以被用在視覺(jué)皮層的接收域中。他們證明了我們大腦中的基本視覺(jué)旋渦 (V1) 使用稀疏性原理來(lái)創(chuàng)建一個(gè)能夠被用于重建輸入圖像的基本功能的最小集合。下面的鏈接是 2014 年倫敦微...
...ng model.CSS盒模型描述了通過(guò) 文檔樹(shù)中的元素 以及相應(yīng)的 視覺(jué)格式化模型(visual formatting model) 所生成的矩形盒子。 基礎(chǔ)盒模型(CSS basic box model) 當(dāng)瀏覽器對(duì)一個(gè) render tree 進(jìn)行渲染時(shí),瀏覽器的渲染引擎就會(huì)根據(jù) 基礎(chǔ)盒模型(CSS bas...

NVIDIA和MIT的研究人員推出了一種新的視覺(jué)語(yǔ)言模型(VLM)預(yù)訓(xùn)練框架,名為VILA。這個(gè)框架旨在通過(guò)有效的嵌入對(duì)齊和動(dòng)態(tài)神經(jīng)網(wǎng)絡(luò)架構(gòu),改進(jìn)語(yǔ)言模型的視覺(jué)和文本的學(xué)習(xí)能力。VILA通過(guò)在大規(guī)模數(shù)據(jù)集如Coy0-70...
...lt;p>NVIDIA和MIT的研究人員推出了一種新的視覺(jué)語(yǔ)言模型(VLM)預(yù)訓(xùn)練框架,名為VILA。這個(gè)框架旨在通過(guò)有效的嵌入對(duì)齊和動(dòng)態(tài)神經(jīng)網(wǎng)絡(luò)架構(gòu),改進(jìn)語(yǔ)言模型的視覺(jué)和文本的學(xué)習(xí)能力。VILA通過(guò)在大規(guī)模...
...院、清華大學(xué)電子工程系的研究人員共同參與的關(guān)于高效視覺(jué)目標(biāo)檢測(cè)的研究已經(jīng)被 CVPR 2017 接收。論文題目是 RON: Reverse Connection with Objectness Prior Networks for Object Detection。研究者包括孔濤、孫富春、Anbang Yao、劉華平、Ming Lu 和陳...
ChatGPT和Sora等AI大模型應(yīng)用,將AI大模型和算力需求的熱度不斷帶上新的臺(tái)階。哪里可以獲得...
大模型的訓(xùn)練用4090是不合適的,但推理(inference/serving)用4090不能說(shuō)合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關(guān)性能圖表。同時(shí)根據(jù)訓(xùn)練、推理能力由高到低做了...




 孫淑建
孫淑建 李世贊
李世贊 鄒立鵬
鄒立鵬














