資訊專欄INFORMATION COLUMN

摘要:是為了大規模分布式訓練和推理而設計的,不過它在支持新機器學習模型和系統級優化的實驗中的表現也足夠靈活。本文對能夠同時兼具規模性和靈活性的系統架構進行了闡述。盡管大多數訓練庫仍然只支持,但確實能夠支持有效的推理。
TensorFlow 是為了大規模分布式訓練和推理而設計的,不過它在支持新機器學習模型和系統級優化的實驗中的表現也足夠靈活。
?
本文對能夠同時兼具規模性和靈活性的系統架構進行了闡述。設定的人群是已基本熟悉 TensorFlow 編程概念,例如 computation graph, operations, and sessions。有關這些主題的介紹,請參閱?
https://tensorflow.google.cn/guide/low_level_intro?hl=zh-CN。如已熟悉 Distributed TensorFlow,本文對您也很有幫助。行至文尾,您應該能了解 TensorFlow 架構,足以閱讀和修改核心 TensorFlow 代碼了。
概覽
TensorFlow runtime 是一個跨平臺庫。圖 1 說明了它的一般架構。 ?C API layer 將不同語言的用戶級代碼與核心運行時分開。
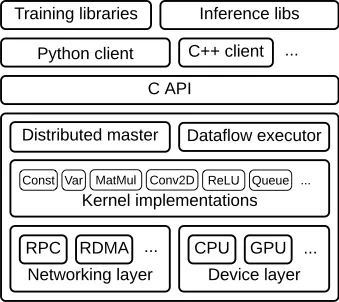
圖 1
本文重點介紹以下幾個方面:
客戶端:
將整個計算過程轉義成一個數據流圖
通過 session,啟動圖形執行
?
分布式主節點
基于用戶傳遞給 Session.run() 中的參數對整個完整的圖形進行修剪,提取其中特定子圖
將上述子圖劃分成不同片段,并將其對應不同的進程和設備當中
將上述劃分的片段分布到 worker services 工作節點服務上
每個 worker services 工作節點服務上執行其收到的圖形片段
工作節點服務 Worker Services (每一任務一個)
使用內核實現來計劃圖形表示的計算部分分配給正確的可用硬件(如 cpu,gpu 等)
與其他工作節點服務 work services 相互發送和接收計算結果
內核實現
執行單個圖形操作的計算部分
圖 2 說明了這些組件的相互作用。“/ job:worker / task:0” 和 “/ job:ps / task:0” 都是工作節點服務 worker services 上執行的任務。“PS” 表示 “參數服務器”:負責存儲和更新模型參數。其他任務在迭代優化參數時會對這些參數發送更新。如果在單機環境下,上述 PS 和 worker 不是必須的,不需要在任務之間進行這種特定的分工,但是對于分布式訓練,這種模式就是很常見的。?

圖 2
請注意,分布式主節點 Distributed Master 和工作節點服務 Worker Service 僅存在于分布式 TensorFlow 中。TensorFlow 的單進程版本包含一個特殊的 Session 實現,它可以執行分布式主服務器執行的所有操作,但只與本地進程中的設備進行通信。
下面,通過逐步處理示例圖來詳細介紹一下 TensorFlow 核心模塊。
客戶端
用戶在客戶端編寫 TensorFlow 程序來構建計算圖。該程序可以直接組成多帶帶的操作,也可以使用 Estimators API 之類的便利庫來組合神經網絡層和其他更高級別的抽象概念。TensorFlow 支持多種客戶端語言,我們優先考慮 Python 和 C ++,因為我們的內部用戶最熟悉這些語言。隨著功能的日趨完善,我們一般會將它們移植到 C ++,以便用戶可以從所有客戶端語言優化訪問。盡管大多數訓練庫仍然只支持 Python,但 C ++ 確實能夠支持有效的推理。
客戶端創建會話,該會話將圖形定義作為 tf.GraphDef 協議緩沖區發送到分布式主節點。當客戶端評估圖中的一個或多個節點時,評估會觸發對分布式主節點的調用以啟動計算。
在圖 3 中,客戶端構建了一個圖表,將權重(w)應用于特征向量(x),添加偏差項(b)并將結果保存在變量中。

圖 3
代碼:
tf.Session
分布式主節點 Distributed master
分布式主節點:
基于客戶端指定的節點,從完整的圖形中截取所需的子圖
對圖表進一步進行劃分,使其可以將每個圖形片段映射到不同的執行設備上
以及緩存這些劃分好的片段,以便在后續步驟中再次使用
由于主節點可以總攬步驟計算,因此它可以使用標準的優化方法去做優化,例如公共子表達式消除和常量的綁定。然后,對一組任務中優化后的子圖或者片段執行協調。
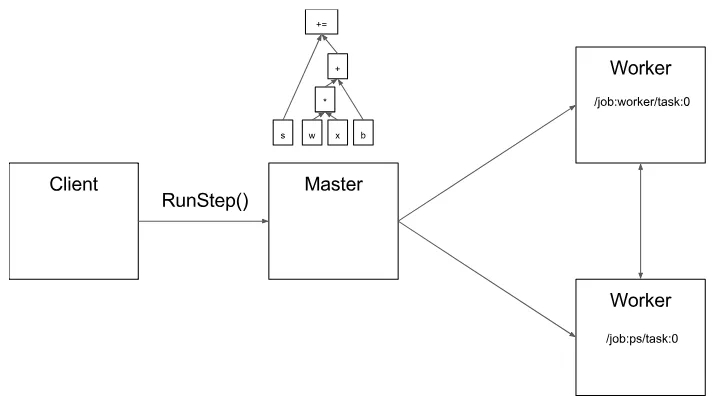
圖 4
?
圖 5 顯示了示例圖的可能分區。分布式主節點已對模型參數進行分組,以便將它們放在參數服務器上。
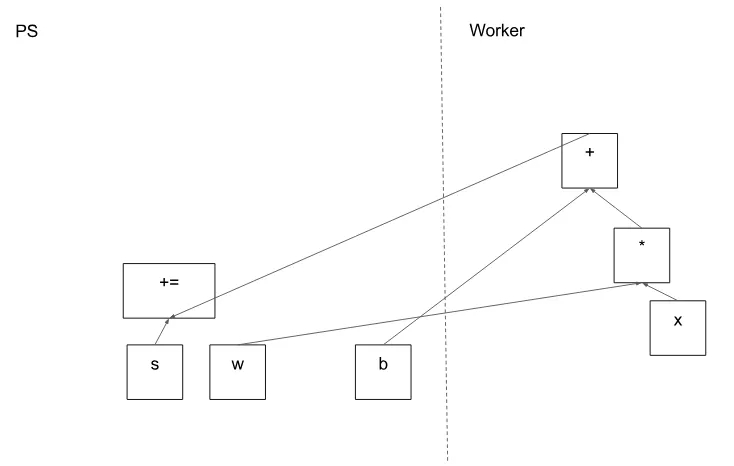
圖 5
在分區切割圖形邊緣的情況下,分布式主節點插入發送和接收節點以在分布式任務之間傳遞信息(圖 6)。
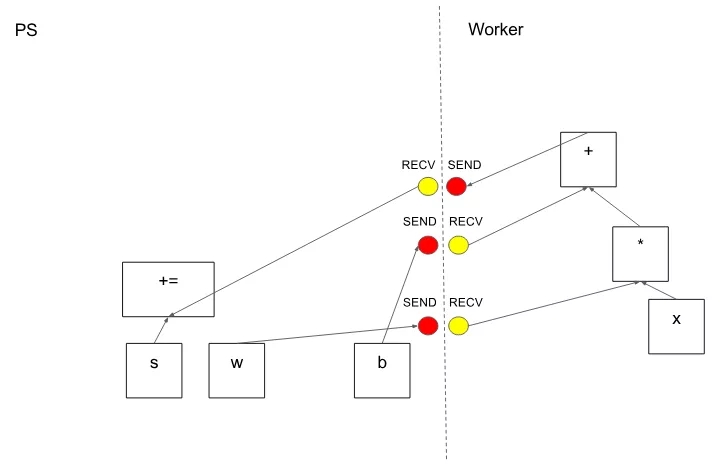
圖 6
然后,分布式主節點將圖形片段傳送到分布式任務。

圖 7
代碼:
MasterService API definition
Master interface
工作節點服務 Worker Service
在每個任務中,該部分負責:
處理來自 master 發來的請求
為包含本地子圖規劃所需要的內核執行
協調與其他任務之間的直接信息交換
我們優化了 Worker Service,以便其以較低的負載便能夠運行大型圖形。當前的版本可以執行每秒上萬個子圖,這使得大量副本可以進行快速的,細粒度的訓練步驟。Worker service 將內核分派給本地設備并在可能的情況下并行執行內核,例如通過使用多個 CPU 內核或者 GPU 流。
我們還特別針對每對源設備和目標設備類型的 Send 和 Recv 操作進行了專攻:
使用 cudaMemcpyAsync() 來進行本地 CPU 和 GPU 設備之間的重疊計算和數據傳輸
兩個本地 GPU 之間的傳輸使用對等 DMA,以避免通過主機 CPU 主內存進行高負載的復制
?
對于任務之間的傳輸,TensorFlow 使用多種協議,包括:
gRPC over TCP
融合以太網上的 RDMA
?
另外,我們還初步支持 NVIDIA 用于多 GPU 通信的 NCCL 庫,請參閱:
tf.contrib.nccl
(https://tensorflow.google.cn/api_docs/python/tf/contrib/nccl?hl=zh-CN)。

圖8
代碼:
WorkerService API definition
Worker interface
Remote rendezvous (for Send and Recv implementations)
內核運行
該運行時包含了 200 多個標準操作,其中涉及了數學,數組,控制流和狀態管理等操作。每個操作都有對應各種設備優化后的內核運行。其中許多操作內核都是通過使用 Eigen::Tensor 實現的,它使用 C ++ 模板為多核 CPU 和 GPU 生成高效的并行代碼;但是,我們可以自由地使用像 cuDNN 這樣的庫,就可以實現更高效的內核運行。我們還實現了 quantization 量化,可以在移動設備和高吞吐量數據中心應用等環境中實現更快的推理,并使用 gemmlowp 低精度矩陣庫來加速量化計算。
如果用戶發現很難去將子計算組合,或者說組合后發現效率很低,則用戶可以通過注冊額外的 C++ 編寫的內核來提供有效的運行。例如,我們建議為一些性能的關鍵操作注冊自己的融合內核,例如 ReLU 和 Sigmoid 激活函數及其對應的梯度等。XLA Compiler 提供了一個實驗性質的自動內核融合實現。
代碼:
OpKernel?interface
聲明:文章收集于網絡,如有侵權,請聯系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4857.html
摘要:在兩個平臺三個平臺下,比較這五個深度學習庫在三類流行深度神經網絡上的性能表現。深度學習的成功,歸因于許多層人工神經元對輸入數據的高表征能力。在年月,官方報道了一個基準性能測試結果,針對一個層全連接神經網絡,與和對比,速度要快上倍。 在2016年推出深度學習工具評測的褚曉文團隊,趕在猴年最后一天,在arXiv.org上發布了的評測版本。這份評測的初版,通過國內AI自媒體的傳播,在國內業界影響很...
摘要:本報告面向的讀者是想要進入機器學習領域的學生和正在尋找新框架的專家。其輸入需要重塑為包含個元素的一維向量以滿足神經網絡。卷積神經網絡目前代表著用于圖像分類任務的較先進算法,并構成了深度學習中的主要架構。 初學者在學習神經網絡的時候往往會有不知道從何處入手的困難,甚至可能不知道選擇什么工具入手才合適。近日,來自意大利的四位研究者發布了一篇題為《神經網絡初學者:在 MATLAB、Torch 和 ...
摘要:而道器相融,在我看來,那煉丹就需要一個好的丹爐了,也就是一個優秀的機器學習平臺。因此,一個機器學習平臺要取得成功,最好具備如下五個特點精辟的核心抽象一個機器學習平臺,必須有其靈魂,也就是它的核心抽象。 *本文首發于 AI前線 ,歡迎轉載,并請注明出處。 摘要 2017年6月,騰訊正式開源面向機器學習的第三代高性能計算平臺 Angel,在GitHub上備受關注;2017年10月19日,騰...
摘要:在嵌入式系統上的深度學習隨著人工智能幾乎延伸至我們生活的方方面面,主要挑戰之一是將這種智能應用到小型低功耗設備上。領先的深度學習框架我們來詳細了解下和這兩個領先的框架。適用性用于圖像分類,但并非針對其他深度學習的應用,例如文本或聲音。 在嵌入式系統上的深度學習隨著人工智能 (AI) 幾乎延伸至我們生活的方方面面,主要挑戰之一是將這種智能應用到小型、低功耗設備上。這需要嵌入式平臺,能夠處理高性...

閱讀 3476·2021-11-25 09:43
閱讀 2624·2021-09-22 15:54
閱讀 597·2019-08-30 15:55
閱讀 982·2019-08-30 15:55
閱讀 2007·2019-08-30 15:55
閱讀 1748·2019-08-30 15:53
閱讀 3476·2019-08-30 15:52
閱讀 2046·2019-08-30 12:55





